

Dx推進の鍵を握る・データドリブン経営
前章で紹介したDXの先進事例のいずれも 「データ」というキーワードが繰 り返し登場しているように、近年、しばしば耳にするようになった「データド リブン経営」。DXへの注目から、データの重要性を実感するようになった方 も多いでしょう。では、具体的にデータをどのように活用すれば、「データド リブン経営」と言えるのでしょうか。これから、前提知識として「データの本 質」を説明した上で、「データドリブン経営とは何か」や「従来型のKKD経 営との違いは何か」について解説するので、データドリブン経営を実践するヒ ントを一緒に探っていきましょう。
データの本質
「画面にこの商品のデータを入力してほしい」 「この顧客リストに、氏名が重 複しているデータが多い」等々、私たちは普段の業務の中で何気なく“データ” という言葉を使っています。『日本国語大辞典』 では 「データ」 という言葉を 次のように定義しています。
- 立論の材料として集められた、判断を導く情報を内包している事実
- コンピューターで、プログラムを運用できる形に記号・数字化された資料
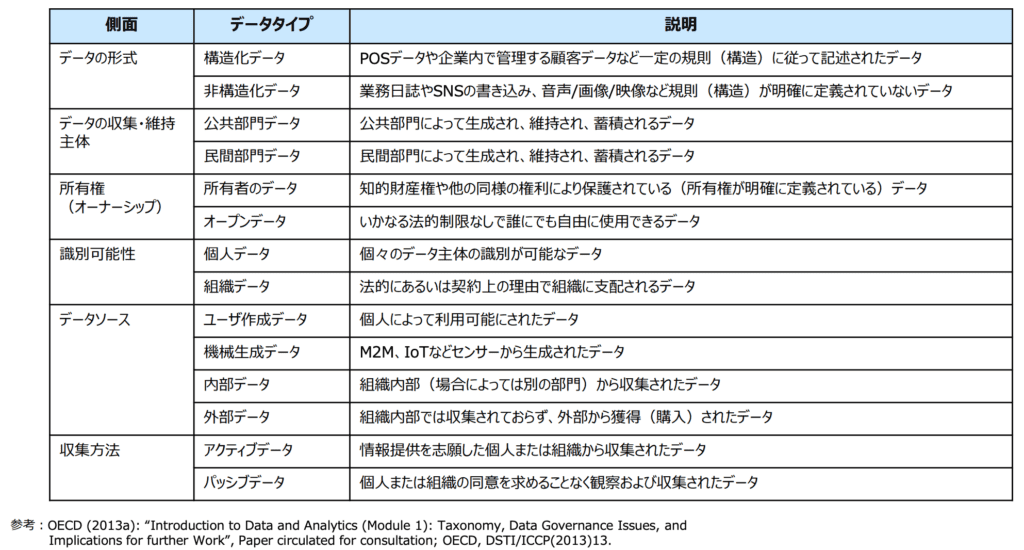
コンピューターが誕生して以来、データというと、「数字」や「コンピューター が処理するもの」と偏重しがちですが、データは元々「立論の材料として客観 的で再現性のある事実や数値」であり、必ずしもコンピューター分野の専門用 語ではありません。また、データの語源がラテン語のdareであり、その言葉 自体が「与える」という意味を持ちますが、「事実や知恵を与える・共有する」という意味合いも含まれているように、データが事実や知恵を共有する手段で あることを認識しておきましょう。データという概念に関しては、次の表のよに様々な側面から分類できます。
ビッグデータとは
ここ数年、DX、データドリブン経営等と切り離せない概念として、耳にす る機会が増えた 「ビッグデータ」。そもそも「ビッグデータ」 とは何でしょうか。 実は、ビッグデータに対する定量的で明確な定義は存在していません。一般的 に、ビッグデータは、その言葉の通りに 「大きいデータ」 です。様々な種類や 形式のデータを含む巨大なデータ群のことです。ビッグデータは単に量が大き いデータ群という印象を受けがちですが、量はあくまでビッグデータの一面に すぎません。ビッグデータは 「Volume (量)」「Variety (多様性)」「Velocity (速度あるいは頻度)」 「Veracity (正確性)」 の 「4つのV」 を高いレベルで備 えていることが特徴です。これからこの4つの特徴を紹介します。
| Volume (データの量)
純粋にデータのボリュームのこと。購入履歴のデータを例に取ると、特定の 1人が特定の商品を1回購入した際のデータの量が小さく、そのデータだけを 見ても、人気商品などの傾向はつかめませんが、多数の人の購入履歴データを分析すれば、どのような商品がどういった状況で売れるかという購買行動の傾 人の将来の購買行動を 向を見出せます。更に、その購買履歴データを使って、 予測したり、広告等で働きかけることで購買行動を引き出したりすることも可能となります。
| Velocity (データの速度)
データが生成される速度のこと。データの生成の速度以外、そのデータをど れだけ素早く処理しなければならないかという要求の速度、更新頻度の高さも 意味しています。SNSや動画共有サイトに投稿されるデータをはじめ、POS データ、交通系ICカードからの乗車履歴データ、特定の感染症の感染者数など、 常に変化する物事については、最新データをリアルタイムで収集・分析しなけ れば、役に立たない場合が多いです。例えば、新型コロナウイルス感染症が流 行する前に、内閣府、総務省などの政府機関は基本的に年に一度のペースで、 人口推計などの統計データを公開していました。しかし、2020年以降、刻々 と状況が変化するコロナ禍においては、1年前のデータを見ても、国、自治体 などの政策立案に全く役立ちません。それを受けて、内閣府が急ピッチで主導 して公開したのはビッグデータを可視化する地域経済分析サイトの「V-RESAS」 です。この「V-RESAS」 の最大の特長はデータの更新頻度です。「V-RESAS」 では人流・飲食・消費・宿泊などの多様なデータが毎週更新のペースで提供さ れており、新型コロナウイルス感染症が地域経済などに与える影響を適時適切 に把握することで、観光関連施設や生活基盤等の維持や、感染症拡大の収束後 に地域経済を活性化させていくための施策立案に大いに貢献しています。
例えば、次のグラフは2019年と現在進行中の同じ月の宿泊者数を比較して 得られた比率(変化率)を表すことで、コロナ禍における宿泊需要の落ち込み と回復の推移状況が概観できます。
| Variety (データの多様性)
データの多様性のこと。様々なデータがあることを指します。従来から企業 内に存在する販売データや在庫データなどに加えて、SNSやモバイル・IoT か ら生成されたデータなどが多様に広がっています。例えば、株式会社 ABEJA が提供している Platform では小売店の店舗にカメラを設置して、来客人数を カウントし、来客者の年齢層・性別をAIで判定しています。次の図に示した 通り、カメラの画像から「女性、過去にもお店に来た客、20~30歳」という 来客一人ひとりの属性を判定すると同時に、「カメラから得られた画像情報」 「ビーコンによる顧客の移動情報」 「IoTデバイスにより扉の開閉状況」 「POS による売上データ」「インターネットから得られた天候情報」を組み合わせて、 多角で販売状況を管理・分析できます。この事例のように、Variety (データ の多様性)の特性によって、様々な種類のデータを収集し、総合的なデータ分 析・活用ができるようになります。
| Veracity (データの正確性)
データの正確性とは、モ 現実世界の対象やイベントを正確に表している程度を 指します。データの利活用においては、データに紛れ込むノイズを排除し、デー タが正確で信用できることを担保しなければなりません。特に、今の世の中で はフェイクニュースなどが溢れており、真実性に疑いのあるデータもたくさん 存在することから、データ自体の信ぴょう性・正確さがますます重要視されま す。不確かな情報や根拠のない推測、個人の思い込み、悪意のある虚偽情報な どが簡単にネット上へと発信されるようになり、これらの偽情報の一部は、ツ イッターで他の人の投稿を再投稿する「リツイート」 などのSNS機能を使って、 短時間で次から次へと拡散されてしまいます。公益財団法人日本財団の調査 (2019年18歳意識調査「第19回調査」調査対象は1,000名)によると、調査 対象者の8割以上が、インターネット上の情報を虚偽だと感じたことがあると 回答しています。真偽を確かめずに情報を拡散したことがある人は26.3%で した。つまり、SNSの情報・データの正確性に対する不安が高まっているこ とに加えて、知らず知らずのうちに信ぴょう性・正確さに欠ける情報とデータ を拡散してしまっていることは明らかになっています。
こうしたフェイクニュースに対抗するために、情報のファクトチェック(事 実確認)をする動きも広がっています。米国では「スノープス」などの専門団 体がネット上の情報などを日々チェックし、真偽を発表しています。日本国内 ではNPO法人のファクトチェック・イニシアティブなどが、ネット上に出回 る情報のうち「誤りなのでは」といったコメントがついたものをAIで自動抽出し、 協力メディアが取材や調査をして事実確認をしてい 抽出された情報について、協力メディアが取材と調査をして実現確認をしています。今後、このような動きがますます広がって、情報の正確性をチェックす るテクノロジーも更に進歩すると予想されています。
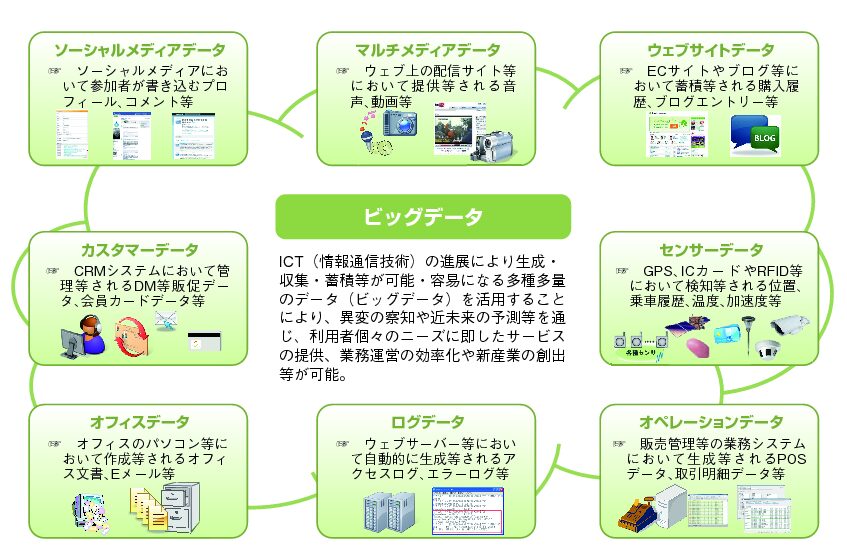
最後に、各業界・分野で活用されているビッグデータの全体像を見ていきま しょう。次の図のように、社内の業務データだけでなく、顧客関連データ、契 約情報、IoTセンサーのデータ、一般消費者の行動データ、交通量・天候デー タ等のいわゆる社会データにまで、ビッグデータデータは多岐にわたっていま す。データの種類も、数値化された構造化データだけでなく、画像、音声など の非構造化データも増加しています。これらのビッグデータを利活用すること で、従来活用できなかったデータを扱えるようになったと同時に、社会、自社、 モノ、ヒトなどの軸で異なるデータを掛け合わせることにより、今までにない 示唆や発想が得られて、より優れた製品・サービスを世の中に送り出す源泉ともなります。
Google の猫に見るビッグデータの重要性
近年、AI(人工知能)の発達が目覚ましく、データ×AIの力で様々な分野 で未来が大きく変化すると確信する人が確実に増えてきています。そのAIの 開発には、「膨大な量のデータの収集が必要」というお話は、誰もが一度は聞 いたことがあるかもしれません。一方で、「なぜAI開発に大量のデータが欠か せないのか」と聞かれたら、ちゃんと答えられるのでしょうか。
そもそも、AIが大量のデータを必要とする背景には、AIブームを支える「機 械学習」という技術が大きく関わっています。機械学習とは、大量のデータから、 「機械」(コンピューター)が自ら「学習」し、データの裏側にあるルールやパターンを発見する方法です。大量のデータの中に見つかるルールやパターンを AIが自ら学んでいくことで、その学習結果をもとに予測や分類を行えるよう になります。その中で、現在最も注目を浴びている機械学習の手法は、「ディー プラーニング」と呼ばれるものです。ディープラーニングの効果を最も印象深 く示したのは「パターン認識」 です。「パターン認識」 とは、画像、自然言語、 音声などを認識する処理のことであり、元々コンピューターが最も不得意な分 野でしたが、「ディープラーニング」 の誕生によって、パターン認識の精度が 飛躍的に向上しました。これについては、「GoogleのAIが猫の画像を見分け られるようになった」、いわゆる 「Google の猫」 のエピソードは有名です。 Google は2012年に 「猫」 の特徴を列挙し、YouTubeのビデオの中から無 作為に画像を取り出して、それをひたすらAIに学習させ続けた結果、AIが画像の中の特徴を自らつかみ、パターン別に分類した上で、「猫」 を見分けられ るようになったのです。AIに学習させた猫の画像の数はなんと1000万枚です。 もちろん、Googleほどのデータ量がなくても、AIは開発できます。ただし、デー タが多ければ多いほど網羅できるパターンの数が増えるため、パターン認識の 精度もそれに比例して上がっていきます。検索エンジン、YouTubeなどのプ ラットフォームから吸い上げた膨大のデータを日々扱っている Googleが、Al のリーディングカンパニーとなったのはそこに理由があります。現在、こうし たパターン認識の技術は広い範囲で活用されて、画像認識による自動車の自動 運転、音声認識を活用したコールセンターの自動化、自動翻訳などが急速に進展しつつあります。
データドリブン経営を支えるDIKW モデル
「データ」と「情報」は普段、しばしば混同して使われがちですが、実は、「デー タ」と「情報」は意味が全く違います。その違いを理解するため、ここで紹介 したいのは 「DIKW モデル」 です。「DIKWモデル」 とは、元々情報工学の分 野において、「情報」を解釈するためのフレームワークであり、それぞれ 「Data」 「Information」 「Knowledge」 「Wisdom」 の頭文字を取って定義されている ものです。「DIKW モデル」 はデータドリブン経営を理解するには重要な概念 となるので、これからそれぞれの定義を見ていきましょう。
Data (データ)
データとは、それ自体では意味を持たない数字や記号などのシンボルを表す ものです。ローデータ、生データとも呼ばれています。
Information (情報)
情報とは、それ自体意味を持たないデータを何らかの基準で整理と意味づけ をし、4W (Who、What、Where、When) の答えとなり得るものです。また、 情報はデータおよび概念により構成され、対象物に対して一定の文脈中で特定 の意味をもつものです。例えば、「1241兆円」 というデータそのものには意 味がありません。しかし「2022年3月末に日本国の借金が過去最大の1241 兆円」と文脈を付け足すと、即座に意味が明らかになります。
Knowledge(知識)
知識とは、情報(Information) を更に整理・体系化したもので、第三者に 教えられるノウハウや知見のことです。つまり、情報から整理された、How の答えとなり得るものです。
Wisdom (知恵)
知恵とは、知識(Knowledge) を正しく理解した上で、自らの判断を加え て行動することで、価値に昇華させたものです。つまり、Knowledge (知識) の中から行動を取る理由 (Why) となり得るものです。
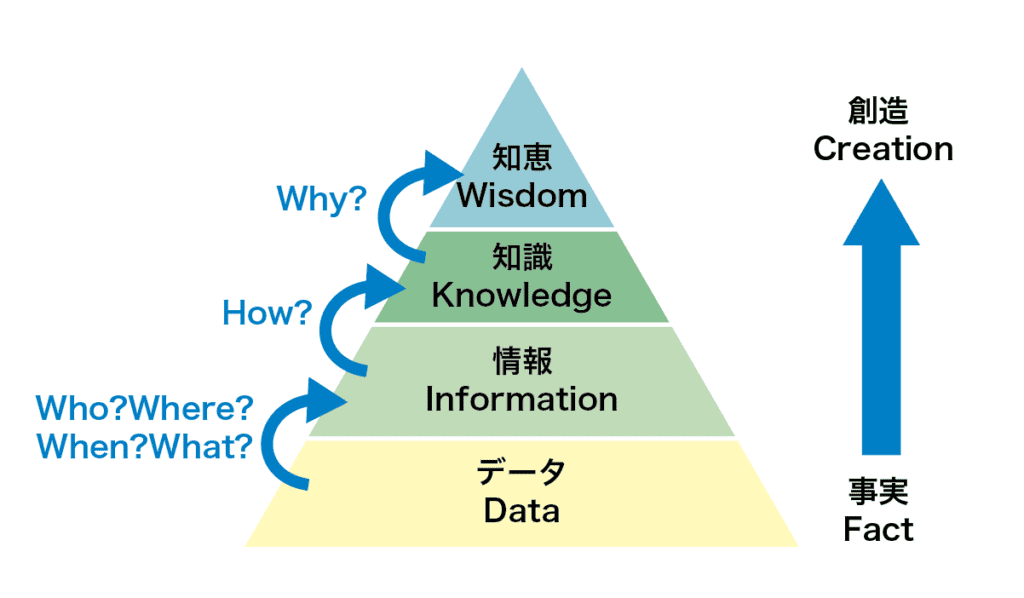
次の図は、DIKW モデルを階層構造で表現したものです。 度が低い概念です。情報や知識では抽象度が上がり、 情報や知識では抽象度が上がり、知恵は最も抽象的な概念 となります。例えば、富士山の高さは「データ」、富士山の地形・気候的な特 徴に関する書籍は「情報」、富士山の山頂に到達するための実用的な登山ガイ ドブックは「知識」と見なせます。更に「知恵」は、自ら富士山を登って、登 山の途中で起きた様々な問題に対処し、知識を応用できる能力と言えます。言 い換えれば、データから情報へ変換する過程で 「Who」 「Where」「When」 「What」の問いを解き、情報から知識に格上げする過程で 「How」に答え、 そして知識から知恵に昇華する際に 「Why」 を紐解くこととなります。
ここからひとつの具体例を挙げて、DIKW モデルの思考プロセスを見てみま しょう。次のように、とある小売り企業に 「乳酸菌飲料の購買データ」がある とします。ステップ ①〜④でDIKW ピラミッドを一番下の「データ」から上 に登っていくと、「データ」 は 「情報」を経て「知識」へ、「知識」を更に「知 恵」へと発展させて、最終的に具体的なアクションまで起こしました。乳酸菌 飲料の購買データを収集・分析し、その分析結果に基づいて、店頭在庫を増や すという意思決定を下したことで、データをビジネス活動につなげた「データ ドリブン経営」とも言えます。
データから価値を生み出すデータバリューチェーン
データバリューチェーン(データの価値連鎖)とは、データの生成、収集、蓄積、前処理、分析、利活用されるまでのプロセスを価値の連鎖として捉え、 データの価値を創出するにはどこに目を付ければよいかを見出すフレームワー クです。次の図に示している通り、データ利活用プロセスの前半の生成、収集、 蓄積のフェーズでは、データから価値を全く生み出していません。データ利活 用プロセス後半の前処理、分析、利活用の順に、利活用のフェーズに近づけば 近づくほど、データが情報 知識 知恵に段階的に昇華させられ、価値を付加 されていきます。これからデータバリューチェーンにおける3つのポイントを 見ていきましょう。
| ポイント① 「Garbage in、Garbage out」(GIGO)原則
データバリューチェーンがDIKWモデルのデータ◆情報⇒ 知識 知恵のビ ラミッド構造と重なっているため、「価値を生み出せるデータ」がバリューチェー ンのスタート時点に存在することが大前提となっています。逆に言えば、品質 の悪いデータや信頼性の低いデータの場合は、そのデータから導き出された情 報から不完全な知識に導かれ、最終的に的外れな知恵となってしまう可能性さ えあります。データ品質に問題がある場合は、「Garbage in, Garbage out (ゴ ミからはゴミしか生まれない)」 (GIGO) 原則に従うことになります。つまり、 川の上流の水が汚れたら、途中のサービス・システムをどれだけ高い品質で作っ たとしても、サービス・システム全体がその汚れた水 (つまり品質の悪いデー タ)の影響を受け続けて、データから創り出された価値を低下させてしまいます。
これと同様に、前項で紹介したビッグデータの4V (データの量、データの 速度、データの多様性、データの正確性)の特性に関しても同じことが言えま す。4Vにおけるレベルが低いデータ(データの量・速度・多様性の不足、! 確性の欠如)からビジネス価値を創り出すことは期待できないでしょう。その ため、データ生成、収集、蓄積、前処理のフェーズで、いかにデータ品質を向上させて、利活用のしやすい形にできるのかが、データ利活用の価値を大きく 左右するポイントになります。
| ポイント② データバリューチェーンにコストがかかる
データ利活用のすべてのフェーズでコストがかかります。例えば、生成、収集、 蓄積のフェーズでは、データ管理費・システム構築費用・運用費、外部データ の購入費、SaaS 利用料などの様々なコストが発生します。データの前処理(デー タ統合・加工など) と分析のフェーズでは、データクレンジング・統合ツール 構築費用、SaaS 利用料、データ分析ツール構築費用、データ整備・分析作業 の人件費などが発生します。また、対象となるデータが本当に価値を生み出せ るかは、一回コストをかけて、データ利活用プロセス全体 (データ生成から利 活用まで)をトライしてみないと、明確な結論が分からないことが多いです。 その際に、データ利活用と相性のよい、前節で紹介したリーン・スタートアッ プのアプローチを取り入れて、必要最小限のコストで小さく始めて、途中結果 に対するユーザーの反応を確認しながら、「成功する見込みはあるのか」「改良 の余地があるのか」 を早期に把握し、何度もトライアンドエラーで軌道修正を 繰り返していくことが有効です。
| ポイント③データの価値が利活用のゴールで決まる
データバリューチェーンから創り出された価値は絶対的ではなく、相対的な ものとなります。データ利活用のゴールを設定し、それに向けて活動した結果、 ビジネス活動に対してどれぐらい定量的・定性的な効果をもたらせるかによっ そのデータの価値が評価されます。つまり、データの価値はデータ利活用 のゴールを達成することによって決まるということです。言い換えれば、デー タ利活用のゴールが極端に低く設定された場合は、そのゴールを達成できたと しても、データバリューチェーンから創り出された価値が低いという事実が変 わりません。適切なゴール設定は、最終的にデータの価値を左右する重要なポ イントとなります。
データドリブン経営の真意
「データドリブン」という言葉の由来は英語のデータ (Data)とドリブン (Driven)です。「データドリブン」を要素分解して解釈すると、「データをえ 点、主軸に物事を駆動する」という意味です。データドリブン〇〇のように、 後に続く言葉 (○○の部分)によって意味を成します。つまり、「データを起点 主軸に何をするのか」 という考え方が重要です。その「何をするのか」によっ て、扱う対象データも変わってくるわけです。例えば、データドリブン経営で 扱うデータは、売上データや市場データ、顧客データなど多岐にわたります。 また、データドリブンマーケティングに着目する場合は、顧客の購入履歴、第 入に至るまでの行動データ、商品購入後の満足度やリピート率、SNSやアンケー トなどのデータが挙げられます。
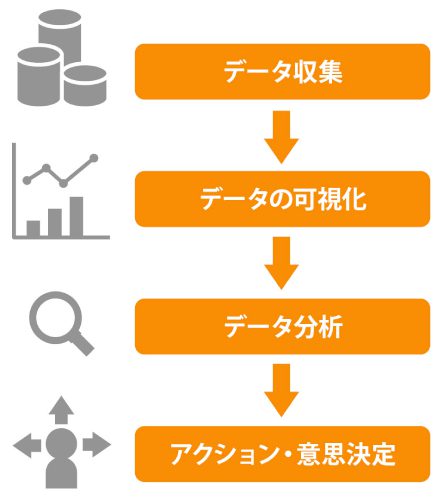
逆に言えば、データを収集・分析することが、組織の意思決定に役立つもの でなければなりません。いくらデータを収集・分析をしたところで、企業の課 題解決または新たな価値創造に関わる意思決定に全く無関係であれば、それが データドリブン経営とは言えません。
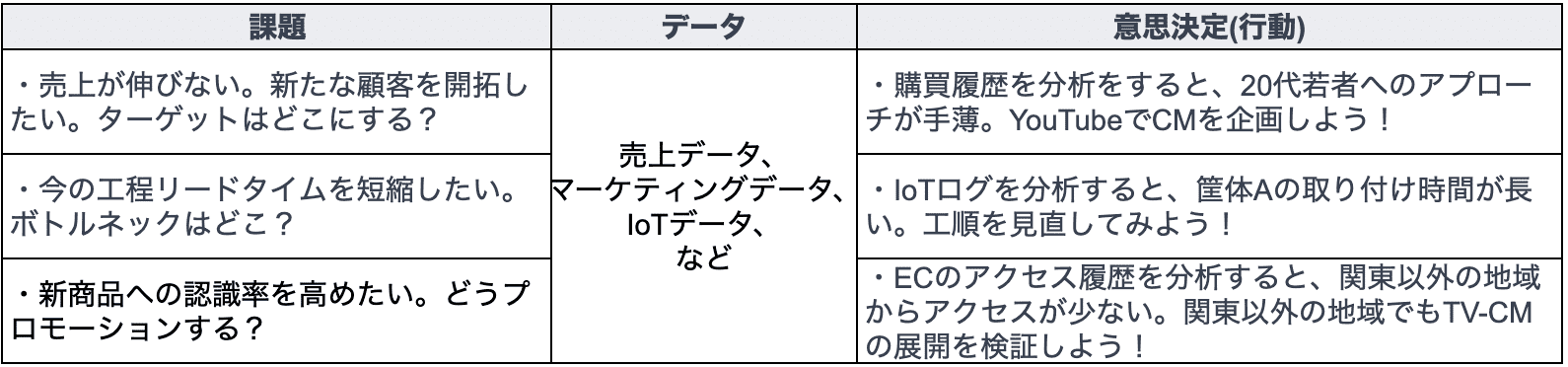
具体的なイメージとしては、次の図のようにビジネス上の課題を起点に、仮 説を立てて、必要なデータ (売上データやマーケティングデータ、IoTデータ、 Web解析データなど) を活用して仮説検証を行った上で、課題解決のための 意思決定を下すことで、具体的な施策や行動につなげていきます。
データドリブン経営が求められる理由
データドリブン経営という言葉が生まれる前から、既に多くの企業は企画立 案や業務改善などにデータを分析し、活用してきました。なぜ今の時代、デー タドリブン経営がより求められているのでしょうか。そこには、以下の3つの 理由が考えられます。
理由① 顧客の価値観の多様化・複雜化
ひとつ目の理由は、顧客の価値観の多様化・複雑化にあります。今の世の中、 モノやサービスが溢れ、エンドユーザーに自社製品・サービスを選んでもらう ことは簡単ではありません。企業間の競争が激化する中で、徹底した顧客体験
(ユーザーエクスペリエンス、UX)の最適化と、 そのための顧客理解が欠か せません。糸 までこうやってきた」 と決めつけてしまうと、 経営者の勘や経験だけに頼り、「自社の顧客はきっとこうである」「今 ・誤ったマーケティング戦略・施 、市場などの外部環境の急激な変化に対 策を招いてしまうだけでなく、消費者、所 応できなくなってしまいます。そこで重要なのは、次の図のような顧客データ の収集・分析・施策といった一連のデータ利活用です。顧客の属性データや購 買データなどを分析し、顧客自身も自覚していない潜在的なニーズを洞察する ことで、顧客の期待通り、もしくはそれ以上の顧客体験を提供することが企業 にとっての競争力の源泉ともなります。
理由②テクノロジーの進歩
2つ目の理由は、テクノロジーの急激な進歩にあります。近年、AI(人工知能)、 IoT、ロボットなど、デジタル技術が急速に進化する中で、現実世界のあらゆ る物事や現象のデータ化が可能になり、膨大な量のデータを蓄積・分析するこ とが容易になったことで、データドリブン経営を行う環境が今まで以上に充実 しています。その中で、「デジタルツイン」という概念を理解することが重要 です。デジタルツインとは、「デジタルの双子」という意味で、現実世界の物体や環境から収集したデータを用いて、仮想空間(デジタル空間) 上に双子の ように現実世界を再現するテクノロジーのことです。
IoTなどで現実空間から収集したデータをもとに、仮想空間上で現実空間の 環境を再現することで、限りなく現実に近い分析やシミュレーションが可能と なります。その分析やシミュレーションした結果を更に現実空間へフィードバッ クすることで、将来起こる変化にいち早く対応することも可能となります。つ まり、仮想空間でシミュレーションを行った結果から、現実世界における将来の変化を予測し、先手を打てるようになるわけです。例えば、ダイキン工業は デジタルツインの機能を備えた新生産管理システムを2020年から本格活用し ています。製造設備に取り付けたセンサーやカメラから収集したデータをもと に、設備の異常やラインの停滞などを予測して、2次元マップに表示することで、 生産ラインの故障検知・予知保全 (連続的に設備の状態を計測・監視し、劣化 状態を把握または予知して部品を交換・修理する保全方法)に活かしています。 こうした変化の予測と事前の対策はデジタルツインに最も期待されている領域 です。
理由③ディスラプター(破壊的企業)の登場
3つ目の理由は、ディスラプターの登場に対する企業側の危機感にあります。 様々な業界においてディスラプターが台頭しており、特にデジタル技術を武器 とするデジタルディスラプターは、これまでと全く異なるビジネスモデルで既 存の業界構造や商習慣に風穴を開け、既存の大企業の優位性を大きく揺るがす 存在となっています。筆者の記憶にまだ新しいのは、2020年にトヨタ自動車 の豊田社長が最高益を打ち出した決算発表の席で「生きるか死ぬか」という強 烈な危機感を露わにした発言がありました。
豊田氏は高い参入障壁を築いて、繁栄を謳歌してきた日本の自動車産業に も、巨大なデジタルディスラプターによる脅威がついに差し迫って来るだろう と見越していたわけです。2022年4月時点に、テスラ1社の時価総額はその 他上位自動車メーカー16社の時価総額合計とほぼ同じです。自動車産業はも はや車というプロダクトの戦いではなく、「CASE」 (Connected [コネクテッド]、Autonomous [自動運転】、Shared & Services [カーシェアリング]、 Electric [電気自動車]の頭文字を取った造語)というデジタル技術とデータ を土台とした戦いに移っています。テスラなどの先進的なデータドリブン企業 はデータを新たに再発明したわけでなく、革新的な方法でデータを利活用する ことで、業界の変革を起こして各分野のトップになったわけです。データとデ ジタル技術を活用し、自社の競争力の維持や新たな付加価値を生み出したいと いう企業側の強いニーズが増えてきていることが、データドリブン経営が強く 求められている要因のひとつともなっています。
テスラと上位自動車メーカー16社の時価総額比較
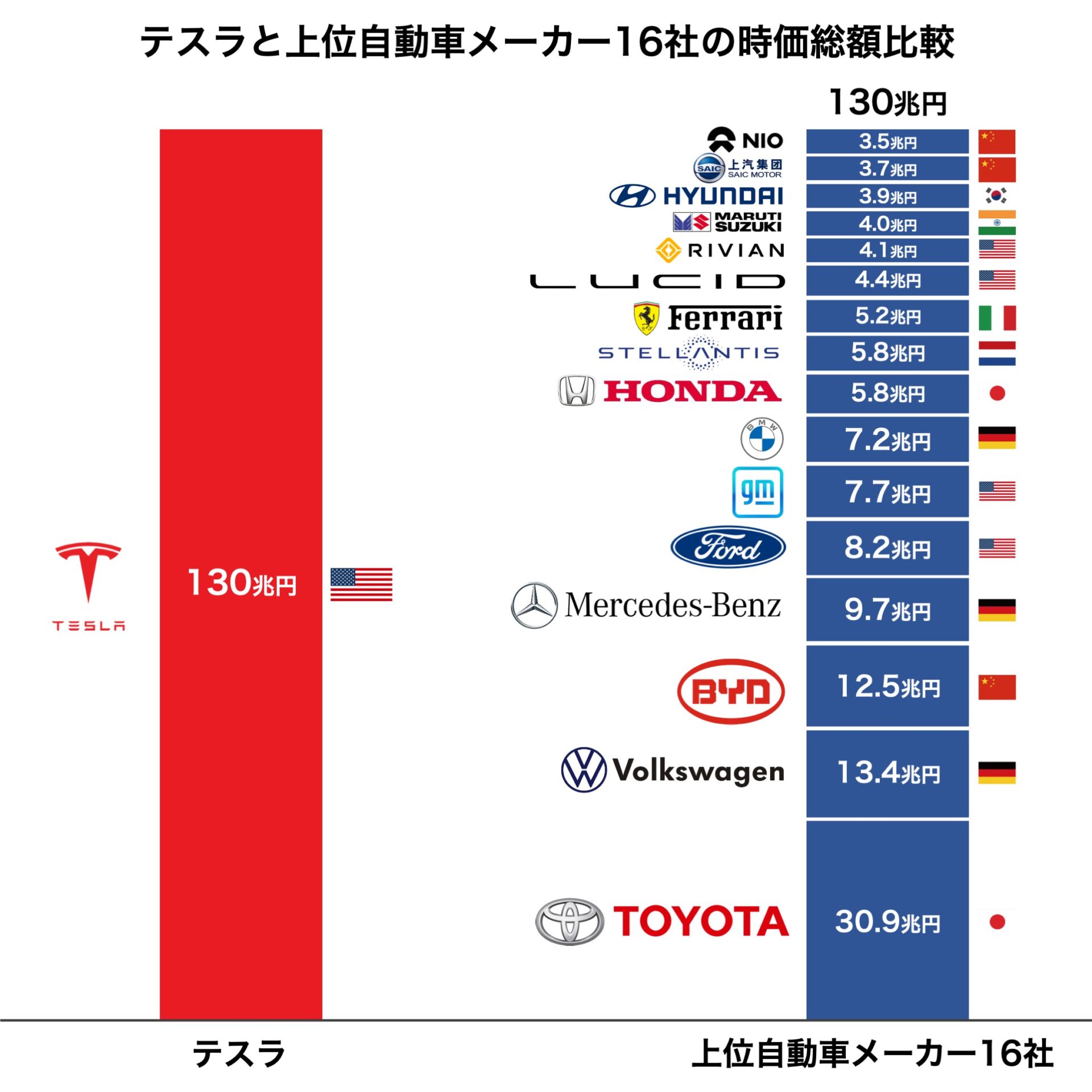 出典:Twitter「企業分析ハック 新しいビジネスの教科書を作る」より、画像をもとに作成 (https://twitter.com/company_hack/status/1517062848111067142)
出典:Twitter「企業分析ハック 新しいビジネスの教科書を作る」より、画像をもとに作成 (https://twitter.com/company_hack/status/1517062848111067142)
データドリブン経営とKKD型経営の違い
一般的に、対立する2つの概念を並べて比較すると、その概念への理解が進 みやすくなります。「勘」「経験」「度胸」で構成される従来の「KKD経営」は 「データドリブン経営」に対立する概念です。これから、KKD型経営と比較し ながら、データドリブン経営の本質を理解しておきましょう。
そもそもKKDとは経験・動・度胸の頭文字を取ってできた言葉で、昔から 日本の製造業を中心に尊重されてきた手法です。例えば、製造業の現場でトラブルができたしに、職人の長年の経験と勘で打開を見つけたりによっ 施策を実行したりすることがKKDの一例です。製造業に限らず、ものづくり大国の日本においては、職人技と言われる暗黙知が経験、勘、度胸による賜 物でもあります。IT業界でも、過去の経験からプロジェクトの工数などを見 積もる KKD法が活用されています。
このような背景から、日本の多くの企業において、経営に関わる意思決定プ ロセスは、古くから特定の人の経験・勘・度胸による暗黙知に頼っている部分 が大きいです。暗黙知とは、「経験や勘、直感などに基づく知識」「簡単に言語 化できない知識」「言語化しても、その意味が簡単には伝わらない知識」など、 つまり経験的な知識となります。暗黙知と対立する言葉として、形式知という 概念があります。形式知とはデータ、数字、ロジックの3つの要素で説明でき る客観的な知識のことです。明確な形式(文章・図表・ 数式など)で表現でき るので、より客観的に物事が捉えられます。データドリブン経営は、形式知を 土台にする経営手法です。それに対して、KKD経営は暗黙知を土台にしており、 経験、勘、度胸の3つの要素によって構成されています。その両者の違いを次 の図のように表現できます。
これから、少し具体例を交えながら、その違いを見ていきましょう。 以前、筆者が担当した案件で現場のヒアリングをしたことがあります。設備 メンテナンス担当者に「交換・修理すべき部品はどのように決められています 」 と聞いたら、「ここの部位の回転回数を見れば、経験上ではどの部品を修
理すべきか大体分かる」というザックリとした答えしか得られませんでした。これは暗黙知による意思決定の典型例です。
皆さんも日常生活ではこの例と同じように、知らず知らずのうちに自身の経験や勘、直感という暗黙知に頼って様々な意思決定を下しているのではないで しょうか。例えば、朝一、傘を持って出かけるかどうか、どのように決めてい るのでしょうか。天気予報の降水確率で判断しているとか、または見上げた空 模様で決めているとか、様々な答えが返ってくるはずです。
もう一歩踏み込むと、天気予報の降水確率で判断している場合は、その判断 基準として、降水確率が何%以上であれば、傘を持っていくのでしょうか。ま た、降水確率ではなく、空模様で判断している場合は空模様、雲行きなどがど ういう様子になっていれば、傘を持っていくのでしょうか。その答えはきっと 十人十色で、個々の経験や勘、直感という暗黙知で無意識に意思決定を行って いるに違いありません。
この「傘を持って出かけるかどうか」という問題を「データドリブン」 的な 目線で捉え直してみたらどうなるのでしょうか。2018年、朝日新聞社が読者 に「降水確率が何%以上だったら傘を持ち歩きますか」と尋ねたところ、「30%」 になるとほぼ半数の人が傘を持って外出することが分かりました。朝日新聞社 のアンケート調査では、次の図のように、降水確率が何%以上であれば、傘を 持ち歩いているかを10%から90%まで10ポイント刻みで読者に選んでもらっ た結果、最も多かったのが「30%」の84人でした。それに、「傘を常備して いる (17%)」と、降水確率が 「10%~30%」で傘を持ち歩く人を合計すると、 全体の49%に相当します。つまり、天気予報で降水確率が30%になると、ほ ぼ半数の人が傘を持ち歩いていることになります。
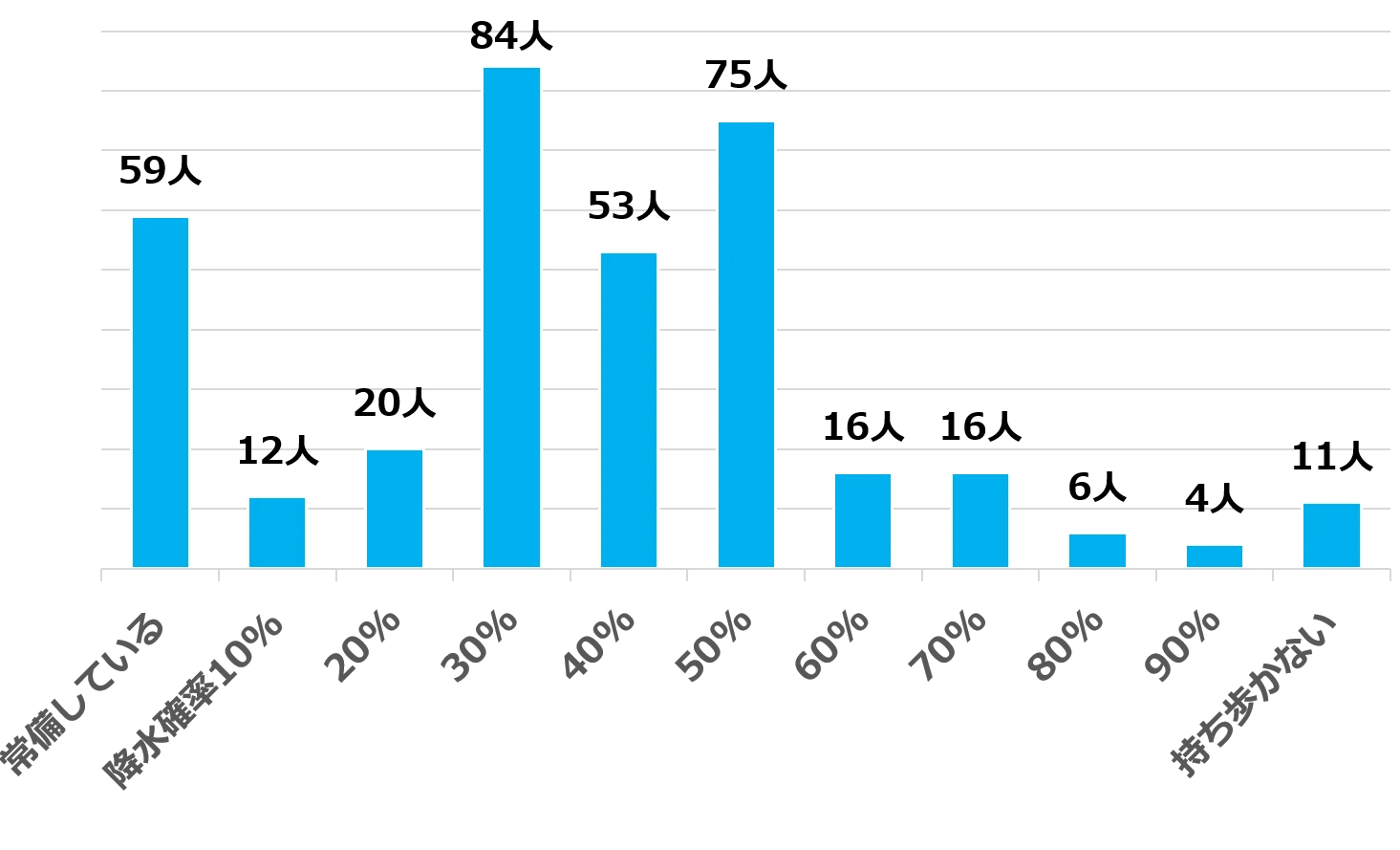
こうした、普段無意識に決めていることについても、アンケート調査で集め たデータをグラフで可視化し、その中身を分析した結果、「降水確率が30%に なると、ほぼ半数の人が傘を持って外出する」 という示唆が得られたのです。 要するに、普段の生活の中で 「データを起点、主軸に物事を駆動する」という 視点を持って物事を捉えているかどうかによって、暗黙知のままで満足してし まうのか、または新たな形式知が得られるのか、その先に全く違う結果が待っ ているはずです。
KKD型経営の4つの問題点
企業を取り巻く経営環境は日々変化しています。企業がそれに対応するため に、常に環境の変化を適切に捉え、分析し、企業の進むべき方向性を決めてい かなければなりません。ダニエル・カーネマン(ノーベル経済学賞の受賞者) の著書『ファスト&スロー」の中に、「組織とは意思決定の工場である」と書 かれている通り、経営者は「意思決定の専門職」と言っても過言ではありませ ん。その企業経営における意思決定はKKD (経験・勘・ 度胸) だけに頼り切 る場合は、どういった問題点があるのか、これから見ていきましょう。
問題点① 属人化
| 属人化とは、意思決定における判断基準、考え方などが特定の人以外では分 お属人化とは、おまう状態を指します。業務と役割の属人化が発生すると、特 定の人がいなければ、仕事が進められなくなってしまうため、ビジネスにおい て大きな問題とも言えます。
これは、特に自分にとって影響力のある人物の意向を気にかける日本の企業 では、決して珍しいことではありません。属人化をもたらす属人的な思考とは、 「データ」 「ファクト」「ロジック」 よりも 「人」を偏重する思考を指します。 例えば、会議などで何かを議論し判断する際には、本来ならばその議題となっ ている事柄自体に対して、ファクトベースで論理的に検討すべきなのに、提案 者など人物の要因を重視する心理傾向になることです。皆さんの会社で「声の 大きい人の勝ち」という会議はないでしょうか。声の大きい責任者や経営者の 暗黙知による意思決定を尊重するのは当然だと思う人もいるかもしれませんが、 その判断を誤ったら、組織が機能不全になり、責任者も経営者も大きな痛手を 負わざるを得ません。ゆえに、本当に有能な責任者や経営者ならば、判断を誤 らないように数字、データ、ロジックという形式知をベースにした真剣な議論 と判断を追い求めるべきです。
たとえ自分の提案に疑問を投げかけられても、それがデータ、ファクトが揃っ ており、理にかなったものであれば、「根拠は何か」 「裏付けとなるデータは何か」 と正々堂々と述べていくだけです。更に、暗黙知による意思決定は、責任者や 経営者のそのタイミングでの直感などによって、類似の事案に対しても異なる 判断が出てくると、意思決定の一貫性にも問題が生じてきます。例えば、朝令 暮改は当たり前、その方針や主張などが二転三転する上司の場合は、部下たち が不信感を抱き、組織全体としての求心力も低下していくのは避けられません。
| 問題点② 精度の低下
人間は情報認知の範囲や処理能力に限界があるため、過去の経験などから無 意識のうちに優先すべき情報を取捨選択する傾向があります。認知心理学で知 られている「確証バイアス」によると、人間は自分が既に持っている先入観や 仮説を肯定するために、自分にとって都合のよいデータや情報ばかりを集める 傾向があります。その結果、必要な情報を広く集められたとしても、ごく限られた、自身にとって都合の良い情報に基づいて意思決定を行うので精度が低下 しかねません。
また、人が何らかの意思決定を行う際に、意思決定となる対象はその時点で 起きている物事とは限りません。例えば、3ヵ月後に行く予定の旅行先を選択 したり、1年後の就職活動を考えたりすることも珍しくないでしょう。その際、 同じ対象であっても、時間的に遠いと感じるか、近いと感じるかによって、重 視するポイントや選択基準が変わる場合があります。例えば、当初、「学問の 専門的知識をしっかりと身につけたい」 という目標をもっていた大学生がいざ 履修登録の直前になると、「単位を取りやすい授業はどれなのか」 という視点 に変えて、講義を選択してしまうことがよくあります。また、「幸せな家庭を 築きたい」と考えていた人が、結婚直前になり、相手の細かな言動や癖に敏感 になり、不安や嫌悪感を抱いたり、気持ちが沈んでしまったりする現象もしば しば起こり得ます。
こうした現象を紐解くための 「解釈レベル理論」 が知られています。解釈レ ベル理論とは、人間は出来事や判断対象の物事に対する心理的距離(時間的距 離、空間的距離、親しさの距離など) が遠い時にはより客観的、抽象度の高い 解釈レベルで考えると対照に、心理的距離が近い時により主観的、表面的な解 釈レベルで考えてしまう傾向があるということです。そうした解釈レベルの違 いが、選択肢の評価や選択の意思決定にも重要な影響を及ぼします。例えば、 新商品の販売計画を例にとると、発売日の直近になればなるほど、競合他社や 市場の些細な動きに対して、経営層が過剰に反応してしまい、根拠なしに計画 を変更した結果、社内のサプライチェーン全体の計画への影響が出てしまうケー スも珍しくありません。
従って、意思決定の精度向上には、意思決定に必要となる情報を収集し、そ の情報を正しく理解した上で、認知バイアスを可能な限りに排除しておくこと が重要です。現在、データとAIを活用した需要予測の取り組みに注目が集まっ ている理由も、こうした「人の認知バイアスの限界」を超えたり、克服したり するところに大きな意義があるからです。
問題点③ スピード感の欠如
KKD経営による意思決定は、想定以上に時間かかるケースがあります。 。住 KKD査を例に取ると、銀行のローン審査担当者は、申請者の自己 宅ローンの事前受社会調査などの情報を可能な限りに網羅的に確認した上で 現金、信用、反対います。これを経験・動だけに頼ってい る 判断するよに時間がかかります。また銀行内で議決裁基準などが形式知化し にまわないその都度に上長の経験・勘による追加判断が必要な場合は、更に時 間を有します。
それとは対照的に、データとAIを活用した住宅ローン審査の場合はどうな るか、ソニー銀行の事例を取り上げて紹介します。ソニー銀行の住宅ローンの AI審査は、過去数年分、数十万件の審査データをAIに学習させ、それに基づ いて審査結果(「可決」または「否決」)を出すというものです。人間が担当す ると2~6日かかるところを、AIだと最短60分で完了しています。しかも、AI による判定と人間による審査の結果はほぼ95%~100%一致していると公表 されています。AI審査はスピードだけではなく、精度の高さも裏付けられて います。こういうスピーディーな審査は利用者にとっても大きなメリットがあ るため、住宅ローンの激しい競争の中でソニー銀行のような先駆者に大事な顧 客を取られてしまう可能性が今後ますます高くなるでしょう。
問題点④ 再現性の欠如
ビジネス全般においては、生産性を上げるのに最も大事なのはビジネスの「再 」を保つことです。分かりやすいのは営業マンのノウハウの例です。とあ る営業マンの成績が優れており、多くの契約をとってくる部門のエースだった としても、その人に部下を付けた時にそれが再現できないのであれば、部門の エースは最後までだた1人の担当者から飛躍できず、組織全体への貢献度も限 られてしまいます。
企業経営の観点で見ると、組織が求めているのは、1人のエースより、エー スから他のメンバーへの形式知の伝授なのです。「職人技の手の動きで他の人 は真似できない。熟練には10年間を要する」「門外不出・秘伝のタレ」などが 継続的に安定したパフォーマンスを維持できればよいのですが、この先の世界 における不確実性が高まっていく中で、暗黙知によるパフォーマンスの安定維持は現実的ではありません。組織として暗黙知を形式知化するといったテーマ に本気で取り組まなければ、職人の匠の技、長年で磨き上げられたノウハウは、 2度と再現できずに喪失してしまいます。ものづくり大国の日本にとってこれ 以上残念なことはありません。
ここまでKKD経営による4つの問題点を見てきました。これからの厳しい 環境変化の時代には 「何とかなるKKD経営」 だけでは、何ともならないと改 めて認識しておきましょう。KKD経営に頼り切るのではなく、特定の人の頭 の中にしか存在しない暗黙知を数字、データ、ロジックで形式知化することで、 合理的な根拠に基づいた企業戦略を策定し、それを着実に実行できる 「データ ドリブン経営」への転換が今の時代に強く求められています。
データドリブン経営とKKD型経営の融合
筆者は暗黙知(経験、勘、直感) による意思決定をすべて否定しているわけ ではありません。数多くのカリスマ経営者は経験・勘・直感による自分流の経 営ノウハウなどを活かして、大きな成功を収め、立派な実績を創り出したのは 事実です。そういったガムシャラな創業経営者の苦労をなくしては、今の経営 基盤は築けなかったでしょう。
しかしながら、「経験、勘、直感」 のKKD経営がこれまで上手く行われて きたからというだけで、今後も同じやり方が通用するとは限りません。そもそ も人間はミスを犯す生き物です。いつも何においても正しく判断できる人が世 の中にいません。これからの時代は、米中貿易戦争、コロナ等による予測不可 能な環境の変化が発生すると同時に、ESG (企業の長期的成長に重要な環境 (E)・社会(S)・カバナンス (G) の3つの観点)、デジタルトランスフォーメー ション (DX) などの産業構造の変革も進む中で、企業経営のあり方が根本か ら問われています。これから重要になってくるのは、暗黙知ベースのKKD経 営と、形式知ベースのデータドリブン経営を融合させ、相互補完し合い、自 にとって最適な意思決定プロセスを確立することです。これを考える上で、ひ とつ有効なアプローチは 「SECI (セキ) モデル」の活用です。「SECI (セキ) モデル」とは、経営学者の野中郁次郎氏が提唱した「ナレッジ・マネジメント」 の基礎理論です。個人的に持っているノウハウを組織的なレベルに共有するこ とで企業の競争力を高める手法として知られています。そのSECI モデルにおける4つのステップを見ていきましょう。
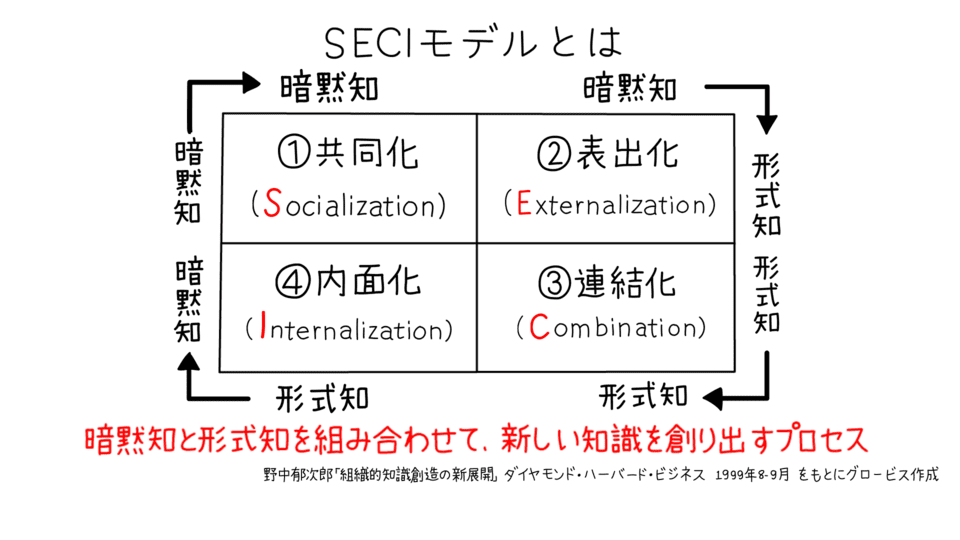
ステップ①共同化(Socialization)
「共同化(Socialization)」とは、暗黙知から暗黙知が生まれるステップです。 暗黙知を暗黙知として伝え、相互理解を深める段階としては、必ずしも言語で 伝える必要がなく、身体や五感を使いながら、勘や感覚などを表現して他者と 共有します。よく挙げられる例は職人の修行において、親方と弟子が一緒に作 業することです。弟子が学ぶべきことはマニュアル化されておらず、親方の仕 事を見よう見まねで覚えるイメージです。
ステップ②表出化 (Externalization)
「表出化(Externalization)」とは、「共同化」 によって得た暗黙知を形式
知に変換するステップです。経験によって得たコツ・ノウハウを、データ、数 字、図、文章で表現し、具体的なグラフ、マニュアルなどに落とし込むことで す。具体的なグラフ、データ、マニュアルが使えれば、組織内ではより簡単に 知識の共有ができます。
ステップ③連結化(Combination)
「連結化(Combination)」とは、「表出化」によって変換された形式知を、既に存在する形式知と結びつけるステップです。例えば、自分が作った業務マ ニュアルを、隣の部署が作ったマニュアルと比較して差分をつかむことで、新 たなヒントが得られ、より汎用的で効率化したマニュアルが作成できます。ま た、このステップから形式知が個人単位から組織のアセット (財産)にレベル アップして、組織のノウハウとして活用できるようになるのがポイントです。
| ステップ④内面化(Internalization)
最後の内面化 (Internalization)は、「表出化」「連結化」の過程を経てまとまっ た形式知が、再度、個人的な暗黙知へと変わっていくステップです。例えば、 新しく作った業務マニュアルの内容を実践しているうち、自分なりの工夫をも とに、新たなコツやノウハウが生まれてくることがしばしばあります。新たに 生まれてきた暗黙知は、いずれレベルアップして再びステップ①の「共同化」 することによって、ほかの人に伝授されていくのです。ここのポイントは、元 の共同化の状態に戻るのではなく、レベルがひとつ上がった暗黙知に変わって いることです。
SECI モデルは4つのプロセスをこなしただけでは完結しません。共同化か ら内面化までを何度も繰り返す必要があります。ステップ①の 「共同化」から ステップ④の「内面化」 がスパイラル構造となっており、絶えず繰り返す(暗 黙知→形式知→暗黙知→形式知・・・) ことによって、よりレベルの高い知識や知 恵を生み出していきます。次の図のイメージのように、KKD経営とデータド リブン経営を SECI モデルで融合させ、暗黙知と形式知が相互補完し合うこと で、組織にとって最適な意思決定プロセスを確立することになります。
データドリブン経営の真意を学ぶ、ワークマンのExcel 経営
データドリブン経営の必要性および考え方を理解したところで、これかその先駆者とも言える株式会社ワークマンの事例から「データトとは何か」という真意をつかんでみましょう。
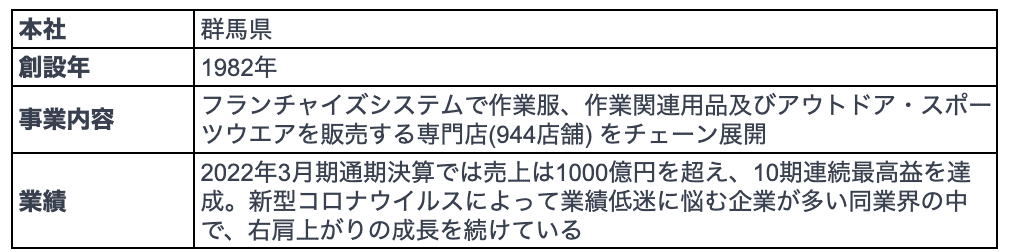
アパレル業界の中で、ワークマンは今最も注目を集めている急成長企業と言っ ても過言ではありません。ワークマンの好調を支える経営手法が「データ経営」 です。データ経営と聞くと、データサイエンスなどの専門家が高度な分析ツー ルを活用している光景が思い浮かぶかもしれません。しかし、ワークマンにお けるデータ経営のアプローチはそれとは真逆です。専門家とツールに頼るので はなく、各店舗の従業員が Excelを使うというシンプルなものです。具体的に、 次の図のように各店舗の従業員がデータ分析の研修を受けた後、どんな製品を 開発すればよいのか、どの製品を店舗に配置すれば売上が上がるのか、といっ た分析を従業員自身がExcelで行い、自ら改善を行っている、いわゆる「Excel 経営」 を実践しています。
この「Excel 経営」 をワークマンに組み込んだのが、2012年に入社した土 屋哲雄氏です。土屋氏の著書 『ワークマン式 「しない経営」』(ダイヤモンド社) によると、当時のワークマンはデータ経営とは全くかけ離れており、同社のデー タ利活用がほぼゼロだったとのことです。社内では決算に必要な数字さえ揃っ ていれば問題ないという考え方が根深く、店舗にある商品の在庫数すら把握で きていないのが当たり前でした。
その背景には、ワークマンは作業服というニッチな市場をターゲットとして おり、創業から40年間、競争せずに事業が続けられていたことがあります。 しかし土屋氏は、その市場はいずれ頭打ちになると強く懸念し、新たなターゲッ トとして低価格の機能性ウェアという空白市場の開拓と、市場開拓のためにデー タ経営を行う方針を打ち立てていきます。土屋氏によると、低価格の機能性ウェ アというブルーオーシャン市場に対して、当然ながら、ワークマンの社内の誰 も知見がない上、社内で経営の逸材がいるわけでもありません。従って、たと え凡人の集団であっても、会社の経営をうまく進める組織を作るには、データ の力を借りて、データを利活用するしかないと土屋氏が考えました。
そこで土屋氏が目をつけたのが表計算ソフトのExcel です。高度なデータ 分析ツールではなく、Excelを選んだ理由は、操作が簡単な上に全社レベルで 既に導入されているという理由でした。Excelであれば、当時はデータ利活用 とは無縁だったワークマンの社員でもあまり抵抗せずに使えるのではないかという極めてシンプルな考え方です。
「Excel 経営」の具体的な取り組みとしては、データ分析の研修を実施し、 社員にExcel関数を書いてもらい、平均90点を取るような試験問題も社員に 解いてもらいました。その研修のテーマも実際に店舗運営で行っている題材で 分析させるなど、実践的な研修プログラムが設計されています。その結果、社 員は Excelに対する距離感がなくなり、「仕事でしっかりと日 というモチベーションを持つようになりました。 Excel
こうしたデータ教育の取り組みは、新人教育でも同様です。新入社員は、入 社1年目は接客や商品知識を身につけますが、2年目から直営店の店長を経験し、 現場でのデータ分析も自ら行います。そこでは売り場の改善成果をデータで検 証したレポートは、毎月提出するように義務付けられています。新人のデータ 教育の総まとめとして、2年目の社員は店長という重要なポジションまで任さ れるようになり、実店舗でデータの活用を本人に体感してもらうようにしてい ます。
仮にデータ教育の成果が出ていないと判断された場合は、教育担当者がその 店舗に駆けつけて、更なるデータ分析の現場指導を行います。ようやく研修を 終えた新入社員は今度スーパーバイザーとなり、指導係として店舗を巡回し、 加盟店のオーナーに対して、データに基づいた品揃えなどの提案を行います。 新入社員の中でデータ分析に秀でた社員がいれば、データ分析専門の部署に配 置転換し、より深くデータに関わることもできます。こうすることで、現場で の分析経験を持つ人材が社内全体に行き渡るようになっています。
ワークマンの「Excel 経営」 から言えるのは、データドリブン経営の向こう にあるのは高価なツールでもなければ、オフィスに閉じ込められた一握りの専 門家でもありません。その拠り所にあるのは現場社員一人ひとりの心です。ワー クマンのデータ教育には現場社員のマインドセットを大きく変える力があり、 現場社員が自ら行動し、自分の頭で考えてデータを活用することで、データド リブン経営を当事者として体得できるようになったのです。こうした現場での 日々の努力による新しい発想を次から次へと生み出し、やがて社員自身の成長 を会社全体の成長につなげることこそ、データドリブン経営の真意です。
まとめ
データドリブン経営は、DX時代のビジネスにおいて決して無視できない重要性を持っています。ビジネスがますますデジタル技術と自動化プロセスに依存する中、正確で詳細な情報を活用することは、ビジネス戦略の重要な要素となっています。NALが長年にわたり開発し、ビジネス展開してきたDXソリューションによって提供されています。データ分析と最新のデータ管理ツールを活用することで、企業はさまざまな情報源から情報を取得し、意思決定プロセスを最適化し、トレンドを予測し、顧客や市場についてより深く理解し、柔軟で効果的な戦略を策定することができます。NALが開発したDXソリューションは、デジタルワークプレース、セールスインテリジェンス、デジタルアシスタント、RPAやローコードツールを含む自社IP製品です。データドリブン経営は、企業自体をより深く理解し、業務を最適化し、顧客体験を向上させ、競争価値を生み出します。データからの情報活用は、強力なツールに加えて、ビジネスの文化の重要な一部であり、現代のビジネス環境での持続的な創造性と革新を促進します。詳細やお問い合わせは、こちらからどうぞ!